






Understanding Word to Vector with CBOW: Turning Words into Vectors
In Natural Language Processing (NLP), Word2Vec is a popular method for turning words into vectors, capturing the meaning and relationships between words. One of the key techniques in Word2Vec is Continuous Bag of Words (CBOW), which predicts a word based on its surrounding context. This blog will break down how CBOW works and provide three example codes to help you implement it.
What is CBOW?
CBOW (Continuous Bag of Words) is a technique that tries to predict a word given its surrounding words (context). It works by using context words (the words around a target word) to predict the target word. This is opposite to the Skip-gram model, where the model predicts the surrounding words based on the target word.
For example, in the sentence: “I love programming and learning,” the CBOW model would try to predict the word “programming” given the context words “I,” “love,” “and,” “learning.”
Why CBOW?
Efficiency: CBOW is faster to train than Skip-gram, especially on large datasets.Good for smaller datasets: It works well when you have a limited amount of training data.
Setting Up Your Environment
To work with CBOW, you’ll need Python and the following libraries:
- Gensim: For Word2Vec and CBOW implementation.
- NumPy: For numerical operations.
- Pandas: For data handling and visualization (optional).
You can install these libraries using the following commands:
pip install gensim numpy pandasExample Code
Example 1: Simple CBOW with Gensim’s Word2Vec
Here’s how to create a simple CBOW model using the Gensim library.
import gensim
from gensim.models import Word2Vec
# Sample sentences
sentences = [
['I', 'love', 'programming'],
['programming', 'is', 'fun'],
['I', 'enjoy', 'learning', 'new', 'things']
]
# Step 1: Train the Word2Vec model using CBOW (default mode)
model = Word2Vec(sentences, vector_size=10, window=2, min_count=1, workers=4)
# Step 2: Get the vector for a word
vector = model.wv['programming']
print("Vector for 'programming':\n", vector)
Explanation:
- We define a few sample sentences.
- The Word2Vec model is trained using CBOW (default mode in Gensim).
- We can access the word vector for “programming” by calling
model.wv['programming'].
Example 2: Training a Custom CBOW Model
In this example, we will customize the parameters to train a CBOW model using a larger context window and vector size.
# Step 1: Train a custom CBOW model
custom_model = Word2Vec(sentences, vector_size=20, window=4, sg=0, min_count=1, workers=4)
# Step 2: Get vectors for words
vector_love = custom_model.wv['love']
vector_fun = custom_model.wv['fun']
print("Vector for 'love':\n", vector_love)
print("\nVector for 'fun':\n", vector_fun)
Explanation:
- We specify the context window size (
window=4) and the vector size (vector_size=20). - Setting
sg=0ensures that we’re using CBOW mode (as opposed to Skip-gram). - We then extract the vectors for the words “love” and “fun.”
Example 3: Finding Similar Words with CBOW
Once the model is trained, you can use it to find words that are similar based on their vector representations.
# Step 1: Train the CBOW model
model = Word2Vec(sentences, vector_size=10, window=2, sg=0, min_count=1, workers=4)
# Step 2: Find similar words to 'programming'
similar_words = model.wv.most_similar('programming', topn=3)
print("Words similar to 'programming':\n", similar_words)
Explanation:
- We train the CBOW model and use the
most_similarmethod to find the top 3 words that are most similar to “programming.” - This gives you insights into the relationships between words learned by the model.
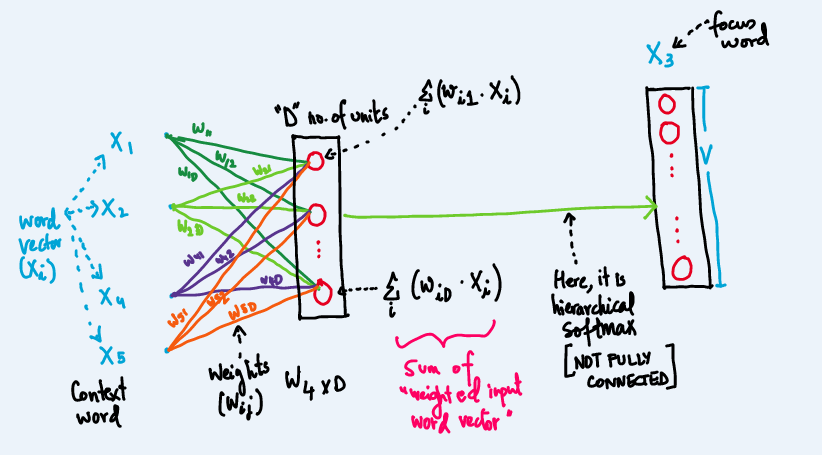
How CBOW Works Behind the Scenes
To better understand CBOW, let’s break down the process:
- Input: The model takes the surrounding words as input (context).
- Hidden Layer: It passes through a hidden layer that generates a weighted sum of the context words.
- Output: The model predicts the target word based on the context.
The word vectors generated by CBOW capture not only the meaning of words but also how they are used in different contexts. Words with similar meanings will have vectors that are close to each other in the vector space.
Conclusion
CBOW is an efficient and powerful way to turn words into vectors in NLP. It predicts words based on context, making it useful for understanding word relationships. With tools like Gensim, it’s easy to implement CBOW in Python. The examples above demonstrate how to create word vectors and explore word relationships using this model.