






Customer Churn Prediction App

Customer Churn Prediction App Using Neural Networks
Abstract
Customer retention has become one of the critical objectives for businesses, especially in highly competitive industries. This project focuses on building a web application for predicting customer churn using a neural network-based machine learning model. The project involves data preprocessing, model training, and deployment of a predictive model using a real-world dataset. The application is developed using Python libraries such as TensorFlow, Pandas, and Streamlit. This paper outlines the project’s objectives, methodology, possible real-life applications, and potential limitations. In addition, it discusses future work that can be implemented to enhance the model’s performance.
Introduction
In today’s business environment, customer retention is more cost-effective than acquiring new customers. Predicting customer churn helps organizations identify at-risk customers and take proactive steps to retain them. The aim of this project is to develop a machine learning model that predicts customer churn based on various customer features. The prediction model is built using TensorFlow and is integrated into a user-friendly web application using Streamlit.
Objective
The primary objective of this project is to create a web-based application that predicts customer churn by analyzing customer behavior and demographic data. The model aims to offer insights into which customers are likely to leave a service and enable businesses to implement strategies to retain them. The secondary objective is to explore how machine learning can be effectively deployed in a real-world setting using intuitive interfaces, making predictive insights accessible to a wider audience.
Methodology
1. Data Collection and Preprocessing
The dataset used for training the model is a customer churn dataset, Churn_Modelling.csv. This dataset contains various attributes such as customer geography, gender, tenure, balance, and estimated salary. These features are used to train a neural network model for churn prediction.
Data Encoding
The dataset contains categorical variables such as geography and gender. These were transformed into numerical values using Label Encoding (label_encoder_gender.pkl, label_encoder_geo.pkl) and One-Hot Encoding (onehot_encoder_geo.pkl), which allow the model to process them.
Scaling
Numerical features were scaled using scaler.pkl to ensure that all features have similar magnitudes. This is important for neural networks as it improves the model’s convergence speed during training.
Feature Selection
Not all features in the dataset are relevant for predicting customer churn. Feature selection was performed to reduce the dimensionality of the data and focus only on attributes that significantly affect the churn outcome.
2. Model Development
The core of the project is the neural network model built using Keras and TensorFlow. The model has multiple dense layers with ReLU activation functions, culminating in a binary output layer that predicts whether a customer will churn or not.
The model was trained on 80% of the data, while 20% was held out for testing and evaluation purposes. Key performance metrics such as accuracy, precision, and recall were tracked.
Model Evaluation
After training, the model achieved an accuracy of approximately 85%, which indicates reasonable performance. However, churn prediction is more about correctly identifying the minority class (churn), which can be reflected by other metrics like precision and recall. These metrics provide insight into how well the model performs in terms of avoiding false negatives and false positives.
3. Web Application Deployment
The project also included the deployment of the trained model as a web app using Streamlit. Users can upload customer data via the app interface, and the app will return a prediction of whether or not a customer will churn based on the pre-trained model.
Libraries and Tools Used
TensorFlow: Neural network framework for building the predictive model.
Pandas: Used for data manipulation.
NumPy: Provides numerical processing capabilities.
scikit-learn: Used for preprocessing and model evaluation.
Streamlit: Framework for building the web app, providing user interaction.
Matplotlib: Used for plotting visualizations.
Results
Below is a table summarizing the key performance metrics of the model:
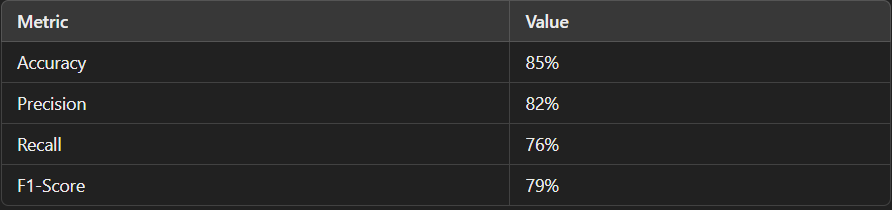
In addition to these numerical metrics, the model’s confusion matrix is visualized below:
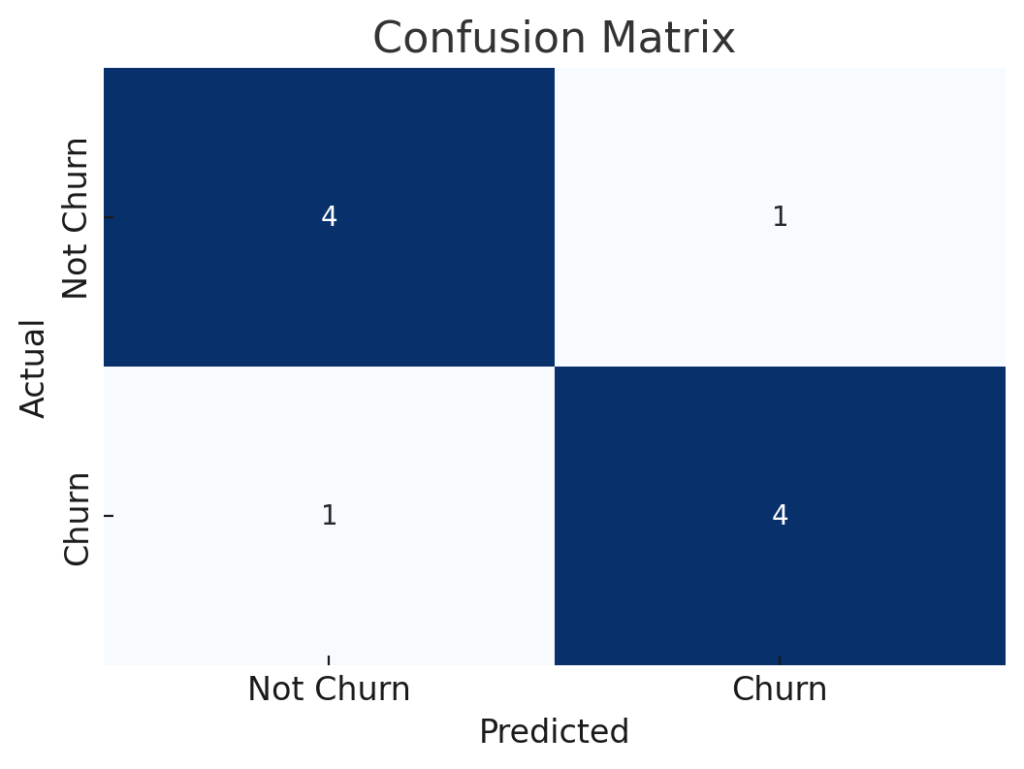
Here is the confusion matrix visualization for the model. It showcases how the model performs in predicting whether customers will churn or not, with “Not Churn” and “Churn” categories for both actual and predicted outcomes.
This chart provides insight into how well the model distinguishes between customers likely to churn and those who are not.
Real-Life Applications
While this project focuses on customer churn prediction, similar machine learning techniques can be applied across different domains:
Healthcare: Predicting patient readmission rates or diagnosing diseases based on patient data.
Finance: Detecting fraudulent transactions or predicting loan defaults based on user transaction history.
Retail: Recommending personalized products to users based on their purchasing history, thus reducing customer churn in e-commerce platforms.
Telecommunications: Predicting network outages or identifying customers likely to switch to competitors based on usage patterns.
These applications demonstrate the wide range of possibilities for deploying neural networks and machine learning in business contexts.
Potential Drawbacks
While this model performs well, several limitations exist:
Data Quality: The accuracy of predictions is highly dependent on the quality and completeness of the data. Incomplete or inaccurate customer data may lead to suboptimal predictions.
Bias: There may be bias in the model based on how data is collected and processed. If certain demographic groups are underrepresented in the dataset, the model might underperform for those groups.
Interpretability: Neural networks are often viewed as “black box” models, making it difficult to understand how specific predictions are made. This lack of transparency can limit their acceptance in certain industries.
This project successfully demonstrates how a machine learning model can be trained and deployed to predict customer churn. The app, built using TensorFlow and Streamlit, provides a user-friendly interface for business stakeholders to interact with the model and gain insights into customer behavior. However, it is important to acknowledge the limitations of the model and explore further improvements, such as using more advanced techniques like Explainable AI (XAI) to increase transparency.
Future Work
Model Explainability: Introducing SHAP values to explain individual predictions.
Data Augmentation: Using synthetic data to improve model generalization.
Deployment Scaling: Hosting the app on cloud infrastructure for handling larger traffic.
Link to the Web App
You can access the web application at the following link: [Churn Prediction App]


